






I. Introduction▲
I-A. Les prérequis▲
Ce tutoriel s'adresse à des lecteurs qui connaissent déjà le langage JavaScript.
Nous n'utiliserons pour ce tutoriel que le langage JavaScript implémenté en standard dans le navigateur (EcmaScript 5) ainsi que sa dernière mouture (EcmaScript 6) également en standard dans le framework Node.js (JavaScript côté serveur).
Aucune bibliothèque complémentaire ne sera nécessaire dans ce tutoriel.
I-B. L'algorithme MapReduce▲
Ce modèle de programmation popularisé par Google permet, à travers deux macro-fonctions, de découper un problème en sous-problèmes (phase de Map), puis de collecter les résultats issus de la résolution de ces sous-problèmes pour fournir un résultat global (phase de Reduce).
Dans un contexte de Big Data, les sous-problèmes issus de la phase de Map sont distribués sur différents nœuds pour être traités en parallèle.
L'essentiel des traitements consiste à créer des listes de clés/valeurs à partir de données brutes et de les trier.
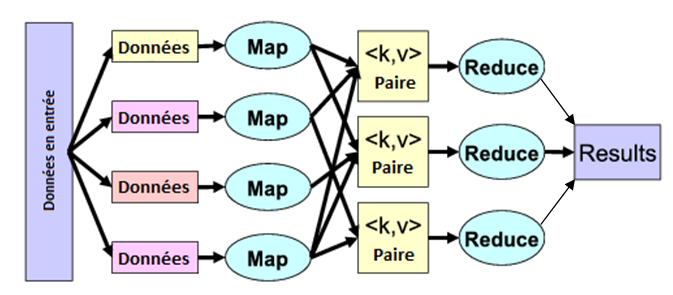
Dans le cadre de cet article, l'exemple pédagogique que nous traiterons ne comprendra qu'un sous-problème traité dans son ensemble par un nœud unique.
I-C. Le cahier des charges▲
Dans son Tutoriel Hadoop, Mickael Baron décrit très clairement le patron de conception MapReduce et nous en propose une implémentation en langage Java sur un exemple pédagogique très simple. L'objet de cet article est de réaliser sur le même exemple un traitement similaire en utilisant JavaScript.
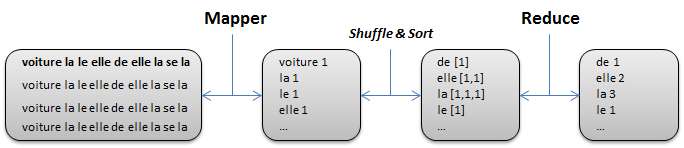
Pour expliquer les concepts de Map et de Reduce, nous prendrons donc l'exemple du compteur de mots fréquemment utilisés, avec une légère variante. Tous les mots sont comptabilisés à l'exception du mot « se ». Le jeu de données à analyser sera le suivant :
var inputString = "voiture la le elle de elle la se la maison voiture";
La figure ci-dessous énumère les différentes étapes qui seront présentées par la suite.
I-C-1. La fonction Map▲
Cette première étape consistera à retourner la liste de clés/valeurs suivante :
[ [ 'voiture', [ 1 ] ], [ 'la', [ 1 ] ], [ 'le', [ 1 ] ], [ 'elle', [ 1 ] ], [ 'de', [ 1 ] ], [ 'elle', [ 1 ] ], [ 'la', [ 1 ] ], [ 'se', [ 0 ] ], [ 'la', [ 1 ] ], [ 'maison', [ 1 ] ], [ 'voiture', [ 1 ] ] ]
On remarque que dans cet exemple, la liste des clés/valeurs est constituée en ajoutant à cette liste le mot rencontré (la clé) et sa valeur qui sera suivant notre règle de gestion de 1 sauf pour la clé « se » qui doit naturellement valoir 0.
I-C-2. les fonctions Sort et Shuffle▲
Ces deux fonctions doivent nous permettre de constituer une liste dans laquelle chaque clé est associée à la liste de toutes ses valeurs. Ce qui doit nous donner dans notre exemple :
[ [ 'de', [ 1 ] ], [ 'elle', [ 1, 1 ] ], [ 'la', [ 1, 1, 1 ] ], [ 'le', [ 1 ] ], [ 'maison', [ 1 ] ], [ 'voiture', [ 1, 1 ] ] ]
on remarque que la clé « se » a disparu conformément aux directives initiales.
I-C-3. La fonction Reduce▲
Cette dernière étape doit présenter un résultat synthétique des opérations précédentes.
Dans le cas de notre compteur de mots, il suffit de sommer pour chaque clé les valeurs de sa liste associée :
[ [ 'de', 1 ], [ 'elle', 2 ], [ 'la', 3 ], [ 'le', 1 ], [ 'maison', 1 ], [ 'voiture', 2 ] ]
II. Les solutions qui existent dans l'écosystème JavaScript▲
II-A. Les modules prêts à l'emploi pour Node.js▲
Sans surprise, on découvre qu'il existe quelques modules Node.js pour réaliser rapidement ce travail. J'utilise personnellement dans mes activités de Big Data le module npm MapReducequi permet aisément d'implémenter l'algorithme de la façon suivante :
var mr = new maprereduce(function(item) {
// la fonction de Map
}, function(result) {
// la fonction de Reduce
}, function(item1, item2) {
// la fonction de Reduce finale globale
});Pour installer ce plugin, on fait classiquement :npm install maprereduce.Mais pour rester dans le JavaScript pédagogique et vraiment comprendre le MapReduce, nous n'utiliserons pas cette bibliothèque. En effet, l'objectif de cet article est de comprendre dans les détails les mécanismes de cet algorithme en l'implémentant en pur JavaScript.
II-B. Implémentation en JavaScript classique (ES5)▲
Le JavaScript se prête particulièrement à ce type de traitement, car ce langage offre un objet Array qui possède un arsenal de méthodes pour les tris, les extractions ou les recherches…
Nous utiliserons les méthodes map() et reduce() de l'objet Array. Et pour la partie shuffle et sort de l'algorithme, on s'appuiera sur les méthodes sort() et filter() de ce même objet.
Voici le code source de l'algorithme qui fonctionne sur tous les navigateurs :
var inputString = "voiture la le elle de elle la se la maison voiture";
// Fonction qui retourne une liste clé/valeur et élimine 'se'
var map = function (str) {
return str.split(" ").map(function(str) {
if (str.valueOf() === "se")
return [str, [0]];
else
return [str, [1]];
}).filter(function(array){
return array[1][0] > 0;
});
}
// Fonction qui regroupe des valeurs par clé
var shuffle = function (arr) {
var sortedArray = arr.sort();
var size = sortedArray.length - 1;
for(var i = 0; i < size; i++) {
if (sortedArray[i][0] == sortedArray[i+1][0]) {
sortedArray[i][1].push(1);
sortedArray.splice(i+1, 1);
size--;
i--;
}
}
return sortedArray
}
// Fonction qui renvoie un tableau de clé-->nombre d'occurrences
var reduce = function (arr){
for (var i = 0; i < shuffledArray.length; i++)
{
shuffledArray[i][1] = shuffledArray[i][1].reduce(function(a, b) {
return a + b;
});
}
}
var mappedArray = map(inputString);
var shuffledArray = shuffle(mappedArray);
reduce(shuffledArray);
console.log(shuffledArray);II-B-1. Implémentation en EcmaScript 6▲
Il n'était pas possible de présenter l'implémentation de cet algorithme sans proposer une déclinaison en ES6 pour utiliser la toute nouvelle notation fonctionnelle.
Les développeurs Node.js utilisent particulièrement cette notation fonctionnelle et ES6 en général. Or c'est bien côté serveur que le Big Data est majoritairement implémenté.
Voici le code commenté en ES6 :
var inputString = "voiture la le elle de elle la se la maison voiture";
// Fonction qui retourne une liste clé/valeur et élimine 'se'
var map = (str) => str.split(" ").map(str => (str.valueOf() === "se") ? [str, [0]] : [str, [1]]).filter(elem => elem[1][0] > 0);
// Fonction qui regroupe des valeurs par clé
var shuffle = (arr) => {
var sortedArray = arr.sort();
sortedArray.forEach((elem, index, arr) => {
while (arr[index + 1] && elem[0] === arr[index + 1][0]){
arr[index][1].push(1);
arr.splice(index + 1, 1);
}
});
return sortedArray;
};
// Fonction qui renvoie un tableau de clé-->nombre d'occurrences
var reduce = (arr) => arr.map(elem => [elem[0],elem[1].reduce((a, b) => a + b)]);
var mappedArray = map(inputString);
var shuffledArray = shuffle(mappedArray);
var reducedArray = reduce(shuffledArray);
console.log(reducedArray);III. Conclusions et remerciements▲
Nous avons vu comment implémenter un algorithme de MapReduce en JavaScript. Et nous avons pu constater que ce langage particulièrement bien gréé pour la manipulation des tableaux offrait une grande perméabilité aux algorithmes de types MapReduce. Cependant, cet article ne doit rester qu'une introduction à ce type d'algorithme et n'a nullement l'ambition de poser les bases du Big Data, ce qui par ailleurs est déjà parfaitement réalisé dans le tutoriel Hadoop de Mickael Baron. En effet, le Big Data doit être traité dans l'écosystème JavaScript en liaison avec des technologies comme Hadoop via des modules prêts à l'emploi pour Node.js. Cette symbiose fera l'objet de tutoriels encore au stade de la rédaction.
Nous tenons à remercier Mickael Baron pour la relecture technique et milkoseck pour la relecture orthographique de cet article.